压缩对于计算机应用是十分必要的,在学习完哈夫曼编码之后我们可以很轻松地根据哈夫曼树结构实现能对任意文件实现压缩/解压的小工具。
通过读取特定文件中字符出现的频数,我们可以利用每次取两颗最小子树的方式构建出哈夫曼树,并由此导出压缩后的哈夫曼编码实现压缩;通过读取压缩文件头中字符出现的频数重建哈夫曼树,并通过相应的哈夫曼编码还原源文件。哈夫曼压缩属于无损压缩,我们可以通过比较解压后的文件哈希码、源文件哈希码的方式验证这一点。
实现过程中需要略微注意的有:
- 文件操作方法(下面实例采用的是C-style的文件操作,即fread, fwrite等基于FILE指针的操作)
- 哈夫曼树构造过程中,选取两颗最小权重子树的方法:像遍历数组那样遍历获取最小值的方法效率低下,下面实现时利用了STL优先队列实现了最小堆。
压缩效率探究
作为数据结构入门课程中要求掌握的代码,我可以预见到其压缩效率必然好不到哪里去。随手扔进去一个CMakeCache.txt文件,可以看到压缩率大概在0.7左右,远低于我们日常使用的7z,估计连zip也打不过。在处理自带压缩编码格式的文件时甚至还会因为携带了额外的文件头而实现“反向压缩的神奇操作”。
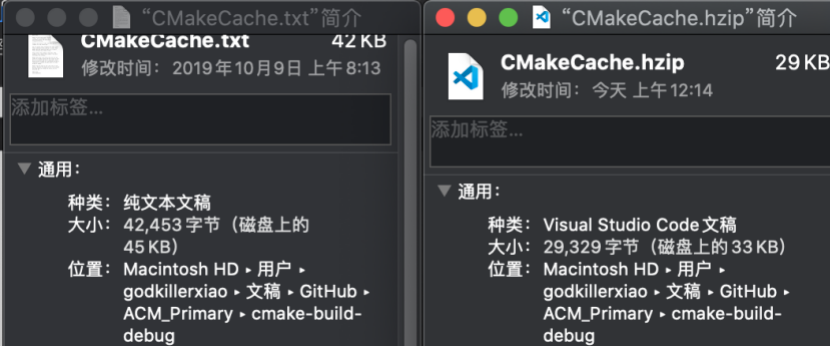

下面给出我对压缩软件实现的一些核心代码:
哈夫曼树与其结点类声明
template <typename T>
struct HuffmanTreeNode{
T _weight;
HuffmanTreeNode *_Left;
HuffmanTreeNode *_Right;
HuffmanTreeNode *_Parent;
explicit HuffmanTreeNode(const T &data)
: _weight(data)
,_Left(nullptr)
,_Right(nullptr)
,_Parent(nullptr){}
};
template <typename T>
struct greater{ // 准备利用优先队列实现最小堆
bool operator()(const T &left, const T &right){
return left->_weight > right->_weight;
}
};
template <typename T>
class HuffmanTree{
private:
HuffmanTreeNode<T> *root;
T _invalid;
void _Create(const T *weight, int sz){
if(sz == 0){
return;
}else if(sz == 1){
if(*weight != _invalid){
root = new HuffmanTreeNode<T>(*weight);
}
}else{
std::priority_queue<HuffmanTreeNode<T> *, std::vector<HuffmanTreeNode<T> *>,
greater<HuffmanTreeNode<T> *> > heap;
for(int i = 0; i < sz; ++i){
if(weight[i] != _invalid){
auto *tmp = new HuffmanTreeNode<T>(weight[i]);
heap.push(tmp);
}
}
HuffmanTreeNode<T> *pLeft, *pRight;
while(heap.size() >= 2){
pLeft = heap.top();
heap.pop();
pRight = heap.top();
heap.pop();
// 取出两个权重最小的结点
auto *pParent = new HuffmanTreeNode<T>(pLeft->_weight + pRight->_weight);
pParent->_Left = pLeft;
pParent->_Right = pRight;
pLeft->_Parent = pParent;
pRight->_Parent = pParent;
heap.push(pParent);
}
// 哈弗曼树建完了,剩下的最后一个节点为树顶
if(!heap.empty()){
root = heap.top();
}
}
}
void _Destroy(HuffmanTreeNode<T> *pRoot){
if(nullptr != pRoot){
_Destroy(pRoot->_Left);
_Destroy(pRoot->_Right);
delete pRoot;
pRoot = nullptr;
}
}
public:
HuffmanTree(const T *weight, int sz, const T &invalid){
root = nullptr;
_invalid = invalid;
assert(weight != nullptr && sz >= 0);
_Create(weight, sz);
}
~HuffmanTree(){
_Destroy(root);
}
HuffmanTreeNode<T> * GetRoot(){
return root;
}
};用于统计每个字符出现频数的FileToken类
struct FileToken{
std::string _strCode; // 压缩后编码
unsigned char _ch; // 当前字符
size_t _count; // 统计字符个数
FileToken(): _count(0){}
FileToken operator+(const FileToken& r){
FileToken temp(*this);
temp._count += r._count;
return temp; // 调用了拷贝构造函数 拷贝出去之后销毁局部对象
}
bool operator < (const FileToken &l) const{
return _count < l._count;
}
bool operator > (const FileToken &l) const{
return _count > l._count;
}
bool operator != (const FileToken &l) const{
return _count != l._count;
}
};核心的FileCompress类声明
class FileCompress{
private:
FileToken _filetoken[256];
void CountFileInfo(FILE *fp);
void FillCode();
void _GenerateHuffmanCode(HuffmanTreeNode<FileToken> *&pRoot);
void WriteHead(FILE *Fwrite, const std::string &strFilePath);
void GetHead(FILE *fp, std::string &FilePostfixName);
void ReadLine(FILE *fp, unsigned char *buf);
void GetPostfixFileName(const std::string &strFileName, std::string &PostfixFileName); // 获取文件名后缀
void GetPrefixFileName(const std::string &strFileName, std::string &PrefixFileName);
void CompressHelp(FILE *Fread, FILE *Fwrite);
void UnCompressHelp(FILE *Fread, FILE *Fwrite);
public:
FileCompress(){
for(size_t i = 0; i < 256; ++i){
_filetoken[i]._ch = i;
_filetoken[i]._count = 0;
}
}
void Compress(const std::string &strFilePath);
void UnCompress(const std::string &strFilePath);
};通过后序遍历(LRD)得到哈夫曼编码:
void FileCompress::_GenerateHuffmanCode(HuffmanTreeNode<FileToken> *&pRoot) {
if(pRoot!= nullptr){ // 后序遍历 LRD 中序 DLR 前序 LDR
_GenerateHuffmanCode(pRoot->_Left);
_GenerateHuffmanCode(pRoot->_Right);
HuffmanTreeNode<FileToken> *pCur = pRoot;
HuffmanTreeNode<FileToken> *pParent = pCur->_Parent;
std::string strCode;
if(pCur->_Left == nullptr && pCur->_Right == nullptr){
while(pParent!= nullptr) {
if (pParent->_Left == pCur) strCode += "0";
if (pParent->_Right == pCur) strCode += "1";
pParent = pParent->_Parent;
pCur = pCur->_Parent;
}
std::reverse(strCode.begin(), strCode.end()); // 倒序输出
_filetoken[pRoot->_weight._ch]._strCode = strCode; // 根据已有哈夫曼树生成哈夫曼编码
}
}
}通过已知编码频数、压缩文件扩展名写入压缩文件文件头
void FileCompress::WriteHead(FILE *Fwrite, const std::string &strFilePath) {
std::string strHead;
GetPostfixFileName(strFilePath, strHead);
strHead += '\n';
size_t LineCount = 0;
std::string strCode;
unsigned char ItoaBuf[30];
size_t idx = 0;
while(idx < sizeof(_filetoken) / sizeof(_filetoken[0])){
if(_filetoken[idx]._count){ // 构造编码表 编码出现次数
strCode += _filetoken[idx]._ch;
strCode += ':';
sprintf((char *)ItoaBuf, "%lld", _filetoken[idx]._count);
strCode += (char *)ItoaBuf;
strCode += '\n';
LineCount++;
}
idx++;
}
sprintf((char *)ItoaBuf, "%d", LineCount);
strHead += (char *) ItoaBuf;
strHead += '\n';
strHead += strCode;
fwrite(strHead.c_str(), 1, strHead.size(), Fwrite);
}压缩核心代码
void FileCompress::CompressHelp(FILE *Fread, FILE *Fwrite) {
fseek(Fread, 0, SEEK_SET);
unsigned char value = 0;
unsigned char ReadBuf[1024];
unsigned char WriteBuf[1024];
size_t BitPos = 0;
size_t WritePos = 0;
while(true){
size_t ReadSize = fread(ReadBuf, 1, 1024, Fread); // 一次至多读1024byte
if(ReadSize == 0) break;
for(size_t readidx = 0; readidx < ReadSize; ++readidx){
std::string &strCode = _filetoken[ReadBuf[readidx]]._strCode;
if(strCode.empty()) return;
for(size_t idx = 0; idx < strCode.size(); ++idx){
value <<= 1; // 左移一位,相当于末尾填0
if(strCode[idx] == '1') value |= 1; // 遇到1写1,不然写上面一行填充的0
if(++BitPos == 8){
WriteBuf[WritePos++] = value;
if(WritePos == 1024){ // 1024byte写满了
fwrite(WriteBuf, 1, 1024, Fwrite);
WritePos = 0;
}
BitPos = 0;
value = 0;
}
}
}
}
// 最后剩下来的写进去
if((BitPos > 0 && BitPos < 8)||WritePos < 1024){
value<<=(8-BitPos);
WriteBuf[WritePos++] = value;
fwrite(WriteBuf, 1, WritePos, Fwrite);
}
}
解压核心
void FileCompress::UnCompressHelp(FILE *Fread, FILE *Fwrite) {
HuffmanTree<FileToken> ht(_filetoken, sizeof(_filetoken) / sizeof(_filetoken[0]),FileToken()); // invalid: 一个默认struct,count为0
HuffmanTreeNode<FileToken> *pRoot = ht.GetRoot();
HuffmanTreeNode<FileToken> *pCur = pRoot;
unsigned char ReadBuf[1024];
unsigned char WriteBuf[1024];
size_t WritePos = 0;
if(nullptr == pRoot) return;
size_t FileLen = pRoot->_weight._count; // 文件长度,由建树过程可知root的weight是所有字符出现个数
while(true){
size_t ReadSize = fread(ReadBuf, 1, 1024, Fread);
if(ReadSize == 0) break;
for(size_t idx = 0; idx < ReadSize && FileLen != 0; ++idx){
int BitPos = 8; // TODO: Can it be unsigned int?
while(BitPos > 0){
--BitPos;
if(ReadBuf[idx] & (1<<BitPos)){
// ReadBuf--1个8位 一开始BitPos为7 1左移7位为1000 0000,
// 这个if用来判断ReadBuf[idx]的第(8-BitPos)位是否为1
pCur = pCur->_Right;
} else pCur = pCur->_Left;
if(pCur->_Left == nullptr && pCur->_Right == nullptr){
// 到达一个哈夫曼树的叶节点
WriteBuf[WritePos++] = pCur->_weight._ch;
pCur = pRoot; // 再回到树根
if(WritePos == 1024){
fwrite(WriteBuf, 1, 1024, Fwrite);
WritePos = 0;
}
--FileLen;
}
if(FileLen == 0 && WritePos > 0 && WritePos < 1024){ // 写完了
fwrite(WriteBuf, 1, WritePos, Fwrite);
break;
}
}
}
}