在不少热门的深度学习应用子领域中,开源工作者们往往会为研究者们提供通用的pipeline与抽象化工具,这能让研究者们更关注与模型的效果(雾...更高效地调参!)而不是与工程上的细节死扣。
实际上,PyTorch官方提供了Ignite这样的高级API,可以通过类似事件驱动编程的形式来调整训练、推理、数据集加载等过程的流水线。
当然,对更细分的领域,Ignite的抽象化程度可能就不如其余的库了,其中对目标检测领域,MMDetection(12.3K Star)可谓是独领风骚,整条目标检测的经典pipeline:从数据集到训练、推理、测试、指标评估全部搭好了!同时,MMDetection也有一定的灵活性,除了预设模块也支持用继承实现的特定模块。
但...这类开源项目的快速迭代会带来不少问题,比如说MMDetection在从v1到v2的路上步子就有点大了:从权重到模型声明语句都经历了翻天覆地的变化,而如果有开源论文恰好用的是V1版本的MMDetection的话,你只有两种选择:
- 老老实实用作者版本配套的环境,但这会有许多问题:且不说你得按老版本重新搭建一套环境费时费力,甚至可能因为设备支持的CUDA版本问题没法成功搭建出老环境来。(如RTX3000系列GPU目前仅支持CUDA11+)
- 给作者的代码做新版本适配
下面我记录一下为CascadeTabNet做v1到v2适配过程中踩到的坑,希望能给同样纠结于此的朋友们一些参考:
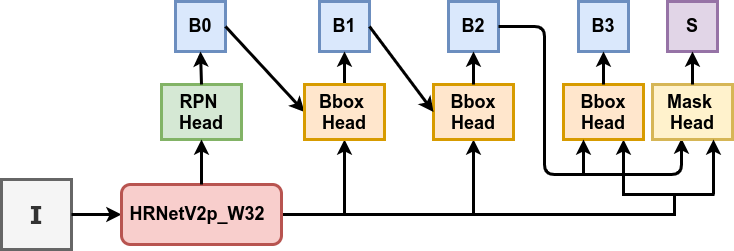
权重升级
MMDetection社区官方提供了v1到v2的升级脚本(小声BB:升级权重的脚本都做了,为啥不给个升级配置文件的脚本呢...),通过python upgrade_model_version.py [旧权重路径] [新权重路径] --num_classes 81可以让v1权重字段适配上v2。
升级脚本会读取权重中的'meta'字段,其中存储了模型训练时的配置,脚本会将此配置读取至临时目录,但注意:CascadeTabNet官方给出的权重epoch_36.pth中的配置文件首行有一行绝对路径/content/drive/My Drive/chunk cascade_mask_rcnn_hrnetv2p_w32_20e.py,这会导致升级脚本验证时报错,可通过以下方法移除:
# 下面步骤仅适用于CascadeTabNet
import torch
ckpt = torch.load('./epoch_36.pth')
info = ckpt['meta']['config'].split('\n')
info = info[1:] # 去掉第一行
ckpt['meta']['config'] = '\n'.join(info)
torch.save(ckpt, './new_epoch_36.pth')(其实也不能怪CascadeTabNet的作者吧,毕竟谁能预见到升级脚本还会读这种东西呢...)
注意,官方在这里提到了,直接转换权重会有略微的表现损失(在1个点左右),对表现有极端要求的建议参考配置文件升级里的内容用v2重新训练!
配置文件升级
MMDetection的抽象化API让我们摆脱了冗长的forward()函数,但其不同版本的兼容问题也让人头痛,下面总结了我遇到的会导致推理无法进行的兼容问题:
num_stages已经移除
报错:
TypeError: __init__() got an unexpected keyword argument 'num_stages'model下不再有num_stages字段:
# v1
model = dict(
type='CascadeRCNN',
num_stages=3,
pretrained='open-mmlab://msra/hrnetv2_w32',
...
# v2
model = dict(
type='CascadeRCNN',
pretrained='open-mmlab://msra/hrnetv2_w32',
...anchor设置方式改动
报错:
TypeError: __init__() got an unexpected keyword argument 'anchor_scales'anchor由三个的独立参数整合为由anchor_generator统一管理:
# v1
anchor_scales=[8],
anchor_ratios=[0.5, 1.0, 2.0],
anchor_strides=[4, 8, 16, 32, 64],
# v2
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),roi_head整合
报错:
TypeError: __init__() got an unexpected keyword argument 'bbox_roi_extractor'bbox_roi_extractor, bbox_head, mask_roi_extractor ,mask_head四个字段整合至roi_head下,而不再与rpn_head等平级出现:
# v1
bbox_roi_extractor=dict(
...
),
bbox_head=[
...
]
mask_roi_extractor=dict(
...
),
mask_head=dict(
...
)
# v2
roi_head=dict(
type='CascadeRoIHead',
num_stages=3,
stage_loss_weights=[1, 0.5, 0.25],
# 这里多了三个字段
bbox_roi_extractor=dict(
...
),
bbox_head=[
...
]
mask_roi_extractor=dict(
...
),
mask_head=dict(
...
)
)所有的num_classes由81变为80
报错:
'SharedFCBBoxHead' is not in ...与目前MMDetection Repo里的预设配置文件对比可得,从文档中的compatibility部分可知v2版本调整了标签以减少classifier的参数量。
SharedFCBBoxHead 变为 Shared2FCBBoxHead
# v1
dict(
type='SharedFCBBoxHead',
num_fcs=2,
...
# v2
dict(
type='Shared2FCBBoxHead',
...target_means, target_stds由bbox_coder管理
# v1
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2],
...
# v2
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
...以上内容我已整理为PR提交至此原作者Repo,并在PyTorch 1.7.0+cu110、torchvision 0.8.1+cu110、MMDetection 2.7.0、mmcv 1.2.1(均为2020年12月09日的最新正式版本)下测试通过。

14 comments
你好,我升级权重的时候,报错:KeyError: 'bbox_head' ,怎么都解决不了,求助!
torch.save('./new_epoch_36.pth', ckpt) 这一行代码,ckpt好像放在前面
感谢,已勘误!
大哥 这问题怎么解决呀 球球了
TypeError: __init__() got an unexpected keyword argument 'bbox_roi_extractor'
你好!首先确认一下你是在改造CascadeTabNet嘛?
其次,这个问题在roi_head整合中有详细提到哦,具体而言,你需要将bbox_roi_extractor移到roi_head下!
改过的代码没有roi_head,但是也报bbox_roi这个错,请问要怎么解决呀,faster rcnn
能给个能跑的权重吗啵啵啵
https://drive.google.com/file/d/10NynXURJP2y1M7ScB0lzXnWcXba30PhM/view?usp=sharing 这里面的new_epoch_24就是我转换后的哦 需要搭配 https://github.com/MrZilinXiao/Hyper-Table-Recognition/blob/main/cascade_mask_rcnn_hrnetv2p_w32_20e.py 这个使用
python upgrade_model_version.py [旧权重路径] [新权重路径] --num_classes 81 后面这个num-classes参数您设的多少啊
设置的是81 也就是默认参数
为啥我num_classes总是显示对不上呢老哥
80和81都试过了嘛?你用的是CascadeTabNet嘛?
对啊,1.2下面好好,升级到2.7就报错,80,81都不行
这边可以在这里贴一下报错 我这边在2.7下调试是通过的