本文记录了为训练检测《德国心脏病》卡片使用Darknet框架在ArchLinux系发行版上训练YOLOv3-tiny的过程,这是因为考虑到Linux更加强大的性能,再者weights格式的权重可以很方便的转为h5格式(我会告诉你是因为我不知道怎么用Keras训练tiny网络嘛?)
安装驱动、CUDA、CUDNN
我在这里只是指出来需要安装这么些个东西,因为在Manjaro里这些事根本不是事:驱动安装时自带,CUDA与CUDNN每个只用一条命令:yaourt -s cuda yaourt -s cudnn。对本项目最新的版本也是符合要求的,只是由于包管理器安装的位置有些差异后续要调整一下。
再次强烈安利Manjaro,绝对是你深度学习的好伴侣,让你不再纠结环境,专注于学习新鲜技术(搬砖)。
一些准备工作
我在此已经准备好了VOC格式的数据集([[项目准备] 论使用深度学习进行卡片识别如何轻松省力获取大量数据 用四张卡片生成大量数据集](https://mrxiao.net/Generating-Datasets-for-Cards-Detection.html "[项目准备] 论使用深度学习进行卡片识别如何轻松省力获取大量数据 用四张卡片生成大量数据集"),先把Darknet拉取下来:git clone https://github.com/AlexeyAB/darknet
根据需要修改以下文件:
- 进入build/darknet/x64/cfg,将yolov3-tiny_obj.cfg拷贝一份到Darknet目录,并作如下修改:
找到两个“[yolo]”,每个[yolo]下面的classes改成数据集类别数(这里是4),每个[yolo]上面的第一个filters改为(classes + 5)x3)(这里是27)。 - 将VOC2007文件夹(已经按VOC格式整理好)放到build/darknet/x64/data/voc目录下,修改本目录下的voc_label.py并运行,得到三个txt,将2007_test.txt,2007_train.txt用
cat 2007_test.txt 2007_train.txt >> train.txt合并:
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["Bananas", "Lemons", "Grapes", "Strawberries"]- 参照如下格式修改cfg/voc.data:
classes= 4
train = /home/xiaozilin/darknet/build/darknet/x64/data/voc/train.txt
valid = /home/xiaozilin/darknet/build/darknet/x64/data/voc/2007_val.txt
names = data/obj.names
backup = /home/xiaozilin/darknet/backup/- 在data新建obj.names文件,每行一个物体类别:
Bananas
Lemons
Grapes
Strawberries- 编译darknet,如果是包管理器安装的cuda与cudnn请确认安装路径,Manjaro系统参照以下格式的Makefile:
GPU=1
CUDNN=1
CUDNN_HALF=0
OPENCV=0
AVX=0
OPENMP=0
LIBSO=0
……
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/opt/cuda/include/
CFLAGS+= -DGPU
ifeq ($(OS),Darwin) #MAC
LDFLAGS+= -L/opt/cuda/lib -lcuda -lcudart -lcublas -lcurand
else
LDFLAGS+= -L/opt/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
endif
endif
ifeq ($(CUDNN), 1)
COMMON+= -DCUDNN
ifeq ($(OS),Darwin) #MAC
CFLAGS+= -DCUDNN -I/opt/cuda/include
LDFLAGS+= -L/opt/cuda/lib -lcudnn
else
CFLAGS+= -DCUDNN -I/opt/cuda/include
LDFLAGS+= -L/opt/cuda/lib64 -lcudnn
endif
endif
……其实就是把/usr/local/cuda换成你的cuda路径,注意GPU、CUDNN全部改为1不然CPU训练即使是tiny也得玩你一万年。
- 开始训练!
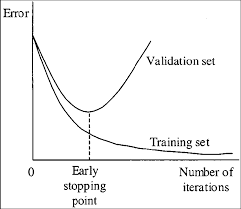
./darknet detector train cfg/voc.data yolov3-tiny-obj.cfg - 漫长的等待,其实相比YOLOv3,tiny训练速度可以说十分之快了,我1000张训练集1066显卡大概1小时loss就降到0.22左右,都快过拟合了……Darknet不像Keras-yolov3那么傻,loss几乎不再下降时它会自动停止训练,每隔1000次iteration会自动保存权重以供挑选。到时我再补充以下如何根据这幅图片选择最佳权重: